Machine Translation (MT) refers to the automatic conversion of text from one natural language to another, using models, techniques, and tools of Natural Language Processing and Computational Linguistics. [note] MT was one of the first non-numerical applications of the computer when the computer was invented in the aftermath of the Second World War.
Initially, development of MT systems was largely politically motivated – between the 1950s and the 1970s, it was regarded by the U.S. government “as a powerful tool in diplomatic efforts related to the containment of communism in the USSR and People’s Republic of China” (Frana, 2021, p.215). Over time, however, MT has become a crucial technology for business purposes, as “an instrument for selling products and services in markets otherwise unattainable because of language barriers, and as a product in its own right” (ibid).
Through decades, there have been varying levels of success for MT, and its relationship with translation studies “has oscillated between hostility and enthusiasm, difference and acceptance” (Kenny, 2020, p.305).
The start of MT development in the 1950s was undoubtedly ambitious, if unpromising, and despite a period of drastic downturn following the (in)famous ALPAC report in 1966, by the first decade of the new millennium it had become “ubiquitous and massively used” (Kenny, 2019, p.428). The use of MT is now often praised for its benefits in multiple respects (e.g., maintenance of linguistic diversity, see Cronin, 2013) and considered a key technology for wealthy global corporations in their business worldwide.
In the meantime, this technology has also been occasionally described as “implicated in the declining fortunes of many freelance human translators” (Kenny, 2019, p.428) (see also Moorkens, 2017), while language service providers used to anecdotally report “significant translator resistance” (O'Brien & Simard, 2014, p.159) and translators were once suspicious of MT (O'Brien & Moorkens, 2014). In Translation Studies, MT has once been controversial and for a long time “relatively neglected in mainstream theory of translation” (Munday, 2009, p.15). There was limited theoretical engagement with MT by translation scholars in the most of the twentieth century (Kenny, 2020), and this indifference was in fact reciprocated by scholars in MT who had rarely crossed their roads with translation studies (Hauenschild & Heizmann, 1997; Toral & Way, 2015).
[Note]
Natural Language Processing (NLP) refers to the handling and understanding of human languages by computational means. There are two major goals for NLP -- to enable human-computer interaction via human languages, and to build application systems that require considerable human language abilities and linguistic knowledge (Kwong, 2015, p.669). NLP is closely related to Computational Linguistics, but the latter is more theoretically oriented (ibid).
References
Cronin, M. (2013). Translation in the Digital Age. Routledge.
Frana, P. L. (2021). Machine Translation. In P. L. Frana & M. J. Klein (Eds.), Encyclopedia of Artificial Intelligence: The Past, Present, and Future of AI (pp. 215-217). ABC-Clio.
Hauenschild, C., & Heizmann, S. (Eds.). (1997). Machine Translation and Translation Theory. Walter de Gruyter.
Kenny, D. (2019). Machine Translaion. In P. Rawling & P. Wilson (Eds.), The Routledge Handbook of Translation and Philosophy (pp. 428-445). Routledge.
Kenny, D. (2020). Machine Translation. In M. Baker & G. Saldanha (Eds.), Routledge encyclopedia of translation studies (pp. 305-310). Routledge.
Kwong, O. Y. (2015). Natural Language Processing. In S. W. Chan (Ed.), The Routledge Encyclopedia of Translation Technology (pp. 563-577). Routledge.
Moorkens, J. (2017). Under pressure: translation in times of austerity. Perspectives, 1-14.
Munday, J. (Ed.). (2009). The Routledge Companion to Translation Studies. Routledge.
O'Brien, S., & Moorkens, J. (2014, 4-6 August). Towards intelligent post-editing interfaces. FIT XXth World Congress 2014, Berlin, Germany.
O'Brien, S., & Simard, M. (2014). Introduction to special issue on post- editing. Machine Translation, 28(3), 159-164. https://doi.org/10.1007/s10590-014-9166-8
Toral, A., & Way, A. (2015). Machine-assisted translation of literary text. Translation Spaces, 4(2), 240-267. https://doi.org/10.1075/ts.4.2.04tor
History of Machine Translation
Before the digital computer
Two early 20th-century inventions that are considered precursors to modern machine translation systems were patented in July and September respectively in 1933. The first is Georges Artsrouni's "mechanical brain," patented in France, which could function as a multilingual dictionary. The second is Petr Trojanskij's invention, which went further by proposing a complete translating machine with a system for encoding and interpreting grammatical functions.
Georges Artsrouni
In 1932, French-American engineer Georges Artsrouni created a translation machine known as the “Mechanical Brain” (cerveau mécanique), which could transform word-root sequences into their equivalents in other languages, in the form of a paper tape. He filed and received a patent for it in July 1933.




Artsrouni's “mechanical brain”. It was a general-purpose machine with many potential applications, but the main application was a mechanical multilingual dictionary.
Picture Source:
Picture 1: https://www.persee.fr/doc/rhs_0048-7996_1965_num_18_3_2427#rhs_0048-7996_1965_num_18_3_T1_0288_0000
Pictures 2-4: https://x.com/ArtsetMetiers/status/1443502363466256386/photo/2
This machine was a general-purpose storage and retrieval device capable of functioning as a multilingual dictionary. Artsrouni's invention featured a memory system using a paper band to store words in multiple languages (bande de réponse), an input device consisting of a keyboard activating a reading head (mécanisme de repérage), a search mechanism (sélecteur), and an output mechanism (mécanisme de sortie) activated in its turn also by the reading head. These four components were driven by a motor, and the whole apparatus was contained in a rectangular box measuring 25x40x21 cm. (See Hutchins, 2004 for details)
The machine could perform word-for-word translations by matching input words with their equivalents in other languages. It also had potential applications in cryptography, railway timetable production, commercial telegraph codes, etc. Despite its innovative design, the outbreak of World War II halted further development.
Key Features (to be revised):
- A mechanical dictionary capable of translating between four languages.
- Memory system using a 40 cm wide paper band up to 40 meters long.
- Input via keyboard and display of translated words on a board.
- Potential for use in various fields including cryptography and data processing.
Reference
Hutchins, J. (2004). Two precursors of machine translation: Artsrouni and Trojanskij. https://aclanthology.org/www.mt-archive.info/IJT-2004-Hutchins.pdf
Petr Petronič Smirnov-Troyanskij
Design of Trojanskij’s translating machine. Source: (Hutchins, 2004; Hutchins & Lovtskii, 2000)
In September 1933, a patent was issued to Russian scholar Petr Petronič Smirnov-Troyanskij for constructing a machine which could select and print words while translating from one language into another or into several others at the same time. His proposal involved a belt with words in different languages and a photographic mechanism to capture the translated word, which could then be typed.
Trojanskij provided proposals for coding and interpreting grammatical functions using universal symbols, envisioning a complete "translating machine". His system aimed to automate both the dictionary lookup and the translation process, incorporating principles that anticipated later developments in computational linguistics and machine translation.
“What sets Trojanskij’s proposal apart from his contemporary Artsrouni was that he went beyond the mechanization of the dictionary by his clear enunciation of some basic processes of translation and by his proposals for ‘logical parsing symbols’. These symbols were intended to represent ‘universal’ grammatical relationships, therefore applicable to any language and when translating between any languages.” (Hutchins, 2004)
Key Features (to be revised):
- Electromechanical device for multilingual translation.
- Detailed coding system for grammatical functions.
- Conceptual framework for a complete translating machine.
- Advanced ideas that foreshadowed modern machine translation technologies.
References
Hutchins, J. (2004). Two precursors of machine translation: Artsrouni and Trojanskij. https://aclanthology.org/www.mt-archive.info/IJT-2004-Hutchins.pdf
Hutchins, J., & Lovtskii, E. (2000). Petr Petrovich Troyanskii (1894–1950): A Forgotten Pioneer of Mechanical Translation. Machine Translation, 15, 187-221.
Invention of the digital computer
In 1946, the ENIAC machine was invented, initially built at the Moore School of Electrical Engineering in the University of Pennsylvania to calculate ballistic firing tables.

Figure: The first programmable general-purpose electronic digital computer, ENIAC, in the Moore School of Electrical Engineering, University of Pennsylvania. Picture source: Encyclopedia Britannica, accessed 13 June 2024 from https://www.britannica.com/technology/ENIAC#/media/1/183842/203028
ENIAC, i.e., Electronic Numerical Integrator and Computer, was the first programmable, electronic, general-purpose computer. ENIAC was designed by two physics professors at the University of Pennsylvania, namely John Mauchly and J. Presper Eckert, and its design and construction was financed by the US Army.
Weaver, Booth and Wiener (1947)
In 1947, American mathematician Warren Weaver and British crystallographer Andrew Booth, both unaware of the precursors of MT such as Artsrouni and Troyanskij (Hutchins, 2010), proposed the tentative ideas for using the newly invented computers to translate natural languages.

Warren Weaver. He was an American mathematician and was at the time the Director of the Division of Natural Sciences at the Rockefeller Foundation.
Picture source: https://resource.rockarch.org/rfphotos_s100_b15_rac_display/

Andrew Donald Booth, a British crystallographer who was at the time visiting various locations in the US where computers were being built. He completed a Rockefeller Fellowship at Princeton in 1947 and returned to Birkbeck College, London University.
Picture source:
Left: https://history.amercrystalassn.org/h-andrew-d-booth
Right: https://www.i-programmer.info/history/people/1253-andrew-booth.html

Picture of Warren Weaver: https://mathshistory.st-andrews.ac.uk/Biographies/Weaver/
Picture of Norbert Wiener: https://www.britannica.com/biography/Norbert-Wiener#/media/1/643306/15215
The possibility of using the computer to translate was also mentioned by Weaver in a letter to Norbert Wiener (who was a cyberneticist), asking whether translation could be treated as a problem of cryptography.
He wrote:
When I look at an article in Russian, I say “This is really written in English, but it has been coded in some strange symbols. I will now proceed to decode.” Have you ever thought about this? As a linguist and expert on computers, do you think it is worth thinking about?
To this, Wiener replied:
I frankly am afraid the boundaries of words in different languages are too vague and the emotional and international connotations are too extensive to make any quasi mechanical translation scheme very hopeful. I will admit that basic English seems to indicate that we can go further than we have generally done in the mechanization of speech, but you must remember that in certain respects basic English is the reverse of mechanical and throws upon such words as 'get,' a burden, which is much greater than most words carry in conventional English. At the present time, the mechanization of language, beyond such a stage as the design of photoelectric reading opportunities for the blind, seems very premature. By the way, I have been fascinated by McCulloch's work on such apparatus, and, as you probably know, he finds the wiring diagram of apparatus of this kind turns out to be surprisingly like the microscopic analogy of the visual cortex in the brain.
Pictures below: Weaver and Wiener correspondence 1947.
PDF Source: https://is.muni.cz/el/phil/jaro2016/PLIN041/um/Weaver-1947-original.pdf



In 1948, Booth worked with Richard Hook Richens, a professional botanist and an early researcher in computational linguistics, on morphological analysis for a mechanical dictionary.
The significance of these efforts:
“It was the first application of the newly invented computers to non-numerical tasks, such as translation. It was the first application of the computer to natural languages, which was later to be known as computational linguistics. It was also one of the first areas of research in the field of artificial intelligence. (Chan, 2023, p.23)”
At that time, the purposes of studying MT (Chan, 2004):
to produce some kind of useful translation
to reveal the workings of language and the human mind as an intellectual challenge
to enrich the prevalent “information theory”
to test the validity of structural and formal linguistics
to analyse linguistic data by the computer
to formalize dictionaries
References
Chan, S. W. (2004). A dictionary of translation technology. Chinese University Press.
Chan, S. W. (2023). The Development of Translation Technology. In S. W. Chan (Ed.), The Routledge Encyclopedia of Translation Technology (pp. 3-41). Routledge.
Hutchins, W. J. (2010). Machine translation: A concise history. Journal of Translation Studies, 13(1-2), 29-70.
Weaver’s Memorandum

Screenshot from PDF. Document Source: https://aclanthology.org/1952.earlymt-1.1.pdf
In July 1949, Warren Weaver wrote a memorandum for peer review outlining the prospects of MT. In this memorandum, he put forward specific proposals for tackling the obvious problems of ambiguity, based on his knowledge of cryptography, statistics, information theory, logic, and language universals.
The memorandum included four proposals:
The problem of multiple meanings might be tackled by examining the immediate context
The problem of translation is formally solvable because written language is an expression of logical character
There is possible applicability of cryptographic methods
There may be linguistic universals and such universals may be mechanically processed
The memorandum met with both scepticism and enthusiasm, but was a “major stimulus to research activity” on MT, resulting in the appointment of Yehoshua Bar-Hillel at MIT for research in MT and the first MT conference (Hutchins, 2000, p.20).
Reference
Hutchins, John. (2000). Warren Weaver and the Launching of MT: Brief biographical note. In J. Hutchins (Ed.), Early Years in Machine Translation (pp. 17-20). Amsterdam: John Benjamins.
Yehoshua Bar-Hillel

In 1951, Yehoshua Bar-Hillel was given the first appointment of a researcher in MT at the Massachusetts Institute of Technology. Bar-Hillel was an Israeli philosopher-mathematician at the Hebrew University of Jerusalem and returned to Israel in 1953.
Picture source https://en.wikipedia.org/w/index.php?curid=1903919
The first MT conference (1952)


PDF fource: MIT conference June 1952 invitations, program (aclanthology.org)
On 17-20 June 1952, the first conference on MT was held at the Massachusetts Institute of Technology. This conference was convened by Yehoshua Bar-Hillel, sponsored by the Rockefeller Foundation, and attended by 18 Specialists.
It led to the first book-length treatment of MT – Machine Translation of Languages edited by William Nash Locke and Andrew D. Booth and published by the Technology Press of the Massachusetts Institute of Technology in 1955.
At the conference, there was “nearly everyone already active in the field” {Hutchins, 2007 #1797, p.31}, and it was already clear at the time that an essential part of MT would be some human intervention (i.e., pre- and post-editing), either as an interim solution or a permanent need (ibid). Various ideas were proposed at the conference, along with suggestions for future activity.
Particularly worthy of mention is that Léon Dostert, one of the major contributors to early MT development, attended the conference being sceptical of MT but became convinced afterwards. He believed that what was needed for MT was a public demonstration of its feasibility so that research funding could be attracted. This led to the Georgetown-IBM experiment.
Details of the conference can be found here: https://aclanthology.org/www.mt-archive.info/50/MIT-1952-TOC.htm
Reference
Hutchins, W. John. (2010). Machine translation: A concise history. Journal of Translation Studies, 13(1-2), 29-70.
Georgetown-IBM experiment (1954)

Picture source: Hutchins (2006)
In January 1954, a public demonstration of a machine translation system from Russian to English was conducted in New York, which was a collaboration between Georgetown University and IBM. This was thus known as the Georgetown-IBM experiment. The experiment showcased not only the first successful use of a computer to translation meaningful texts, but also the first use of the computer to process natural language rather than to calculate numbers.
Its demonstration of the potential of computers to handle linguistic tasks has set a precedent for later advancements in language processing. Although the system operated on a limited scale—translating a vocabulary of 250 words and using only six grammar rules and 49 sentences—it generated significant public interest and media coverage.
Hutchins (2006) describes the publicity of the experiment and the excitement aroused by it as follows:
It was probably the most widespread and influential publicity that machine translation (MT) has ever received,2 and it was undoubtedly the first non-numerical application of the newly invented ‘electronic brains’ that most people had heard of. Translation itself was a largely unknown ‘art’ and the prospect of a machine capable of ‘deciphering’ foreign languages was exciting. The demonstration raised expectations of fast and easy international communication in a world that had already become divided by confrontations and misunderstandings between the United States and the Soviet Union. (p.1)
Reports of the experiment in media:
New York Herald Tribune: 8 January 1954, p.1, https://aclanthology.org/www.mt-archive.info/NYHT-1954-Ubell.pdf
“It’s all done by machine. Words go in Russian, English sentences comes out.”
“A huge electronic ‘brain’ with a 250-word vocabulary translated mouth-filling Russian sentences yesterday into simple English in less than ten seconds.”
New York Times: 8 January 1954, p.1, col.5, https://aclanthology.org/www.mt-archive.info/NYT-1954-Plumb.pdf
“A public demonstration of what is believed to be the first successful use of a machine to translation meaningful texts from one language to another took place here yesterday afternoon.”
Key figures in the project included Léon Dostert from Georgetown University, who was instrumental in conceptualizing the experiment, Paul Garvin from the same university, and IBM's Cuthbert Hurd and Peter Sheridan. The experiment aimed to demonstrate the feasibility of machine translation, particularly for translating Russian, a language of strategic interest for the US during the Cold War.
Léon Dostert – Initially skeptical, he became a strong advocate of machine translation and played a pivotal role in the Georgetown-IBM project.

Léon Dostert (May 14, 1904 – September 1, 1971), a French-born American scholar of languages and a pivotal proponent of machine translation. Picture Source: https://www.oxy.edu/magazine/issues/fall-2015/trials-and-triumphs-leon-dostert-28
In 1952, Dostert was invited to the first conference on machine translation at MIT, where he attended as a sceptic but “returned as an enthusiast determined to explore the possibilities of machine translation” {Hutchins, 2004 #5699, p. 102}. Subsequently, Dostert contacted the founder of IBM, who was his personal acquaintance, for a collaboration on the demonstration of the feasibility of MT in a practical experiment. This was to be led by Dostert himself and Cuthbert Hurd, while the linguistic analysis for the experiment was conducted by Paul Garvin and the computer programming by Peter Sheridan.
Cuthbert Hurd

Picture source: https://teknoloji-tasarim.com/cuthbert-hurd/
Cuthbert Corwin Hurd (April 5, 1911 – May 22, 1996) was an American computer scientist and entrepreneur, who was instrumental in helping the International Business Machines Corporation develop its first general-purpose computers. (Description from Wikipedia)
Machine: IBM 701

Picture Source: https://www.computerhistory.org/timeline/1953/#169ebbe2ad45559efbc6eb35720ada17
The computer used for the experiment was IBM 701. This machine was described as a “huge electronic ‘brain’” which filled “a room as big as a tennis court”. (Ebell E, 1954, New York Herald Tribune). All programming in the experiment was in either machine code, i.e., binary digits, or in assembly language, and each character was coded by 7 bits.


Data was inputted to the machine in the form of punched cards. Picture source: (Hutchins, 2006)
The demonstration involved inputting Russian sentences via punched cards, which the machine then translated almost instantaneously into English. Despite its limited scope, the experiment raised expectations for future developments in automatic translation systems. Subsequent reports highlighted the potential of machine translation to revolutionize how languages are processed and translated, although they also acknowledged the significant work that was still required to expand the system's capabilities.
References
Hutchins, John. (2006). The first public demonstration of machine translation: The Georgetown-IBM system, 7th January 1954. Expanded version of the paper entitled "The Georgetown-IBM experiment demonstrated in January 1954" and presented at the 6th Conference of the Association for Machine Translation in the Americas, Washington DC, USA, 28 September - 2 October, 2004.
Hutchins, John. (2004). The Georgetown-IBM experiment demonstrated in January 1954. In R. E. Frederking & K. B. Taylor (Eds.), Machine Translation: From Real Users to Research - Proceedings of the 6th Conference of the Association for Machine Translation in the Americas, Washington DC, USA, 28 September - 2 October, 2004 (pp. 102-114). Berlin: Springer.
First journal: Mechanical Translation (1954)

PDF source: https://mt-archive.net/50/MechTrans-1-1-1954.pdf
In March 1954, the inaugural issue of Mechanical Translation was published at Massachusetts Institute of Technology, as the first journal in the field of machine translation. This was edited by Victor Yngve and supported by a grant from the Rockefeller Foundation. The journal carried “some of the most significant papers until its eventual demise in 1970” (Hutchins, 2010, p. 32).

Victor Yngve (1920-2012). Yngve was a major contributor in computational linguistics and natural language processing. In addition to his contributions to machine translation, he was also the designer and developer of the first non-numerical programming language (COMIT), and an influential contributor to linguistic theory. (see, e.g., Hutchins, 2012)
References
Hutchins, W. John. (2010). Machine translation: A concise history. Journal of Translation Studies, 13(1-2), 29-70.
Hutchins, John. (2012). Obituary: Victor H. Yngve. Computational Linguistics, 48(3), 461-467.
First doctoral thesis on MT (1954)

Anthony Gervin Oettinger’s PhD thesis, completed in 1954 at Harvard University, was considered the first doctoral thesis on machine translation {Chan, 2004 #1881, p.293}. The study was focused on the design of a Russian mechanical dictionary, which was considered the fundamental component of MT. At the beginning of the thesis, he wrote:
An automatic dictionary is the fundamental component of an automatic translator. It may be used independently to produce rough translations of technical texts for direct use by specialists in the subject matter of the texts. This thesis is a report on the first steps in the design of an automatic Russian-English technical dictionary.

Picture source: https://en.wikipedia.org/wiki/Anthony_Oettinger#/media/File:Ottenger_200x300.jpg
Anthony Gervin Oettinger was a German-born American linguist and computer scientist. He headed a research team on machine translation at Harvard.
Reference
Chan, Sin-wai. (2004). A dictionary of translation technology. Hong Kong: Chinese University Press.
First book on MT (1955)
In 1955, the first book-length treatment of MT – Machine Translation of Languages, edited by William Nash Locke and Andrew D. Booth, was published by the Technology Press of the Massachusetts Institute of Technology in 1955. The foreword of this publication was written by Weaver, where he expressed his optimism for the “new Tower of Anti-Babel” which was being constructed. Here, Weaver described MT as helping with the task of making the essential content of documents available to a reader who does not understand the language in which they are written. As Hutchins {, 2000 #5716, p.20} rightly states, “so it has proved”.

The first book-length treatment of a field of growing significance. Picture source: https://archive.org/details/machinetranslati0000will/mode/2up

Foreword by Warren Weaver. Picture source: https://archive.org/details/machinetranslati0000will/mode/2up
The book also included Weaver’s 1949 Memorandum, the experiments conducted by Booth and Richens, some of the papers presented at the first MT conference in 1952, and contributions from Bar-Hillel, Dostert, Oettinger, Reifler, and Yngve.
References
Hutchins, John. (2000). Warren Weaver and the Launching of MT: Brief biographical note. In J. Hutchins (Ed.), Early Years in Machine Translation (pp. 17-20). Amsterdam: John Benjamins.
Start of MT in China (1956)
In 1956, machine translation as well as the mathematical aspects of natural language was listed in the Chinese government’s Guidelines for Scientific Development (1956-1967年科學技術發展遠景規劃綱要), which signified the beginning of MT research in China {cf \Dong, 1988 #5726}. At that time, as China was politically inclined to Russia, research on MT “started with a Russian-Chinese translation algorithm jointly developed by the Institute of Linguistics and the Institute of Computing Technology” {Chan, 2004 #1881, pp.294-295}.
The first experimental MT system in China was demonstrated in 1959, which was the fifth demonstration in the world {Dong, 1988 #5726, p.86}. This was a Russian-to-Chinese translation system containing 2030 words in the dictionary and 29 sets of grammar rules (ibid).

Guidelines for Scientific Development, which was implemented in 1956. Source of this screenshot: https://www.most.gov.cn/ztzl/gjzcqgy/zcqgylshg/200508/t20050831_24440.html
This document is also available from: https://zh.wikisource.org/zh-hant/1956-1967%E5%B9%B4%E7%A7%91%E5%AD%A6%E6%8A%80%E6%9C%AF%E5%8F%91%E5%B1%95%E8%BF%9C%E6%99%AF%E8%A7%84%E5%88%92%E7%BA%B2%E8%A6%81
References
Dong, Zhendong. (1988). MT research in China. In D. Maxwell, K. Schubert, & T. Witkam (Eds.), New Directions in Machine Translation (pp. 85-91). Dordrecht-Holland: Foris Publications.
Chan, Sin-wai. (2004). A dictionary of translation technology. Hong Kong: Chinese University Press.
Association for Computational Linguistics (1962)
In 1962, the Association for Computational Linguistics (ACL) was founded under the name of the “Association for Machine Translation and Computational Linguistics” (AMTCL), as an international scientific and professional society for researchers working on problems involving natural language and computation. The association changed its name to ACL in 1968. Every summer, the association holds an annual meeting on computational linguistics in locations where this area is studied as a significant discipline.

Screenshot of the ACL webpage. Source: https://www.aclweb.org/portal/acl
The association publishes a journal named Computational Linguistics, which is “the longest-running publication devoted exclusively to the computational and mathematical properties of language and the design and analysis of natural language processing systems” (ACL website).
Computational Linguistics, screenshot from https://direct.mit.edu/coli
Termination of Georgetown project 1963)
In March 1963, the Georgetown machine translation project, the largest project on this topic in the United States, was terminated.
ALPAC and drastic cut in funding in the US (1964, 1966)
In 1964, the Automatic Language Processing Advisory Committee (ALPAC) was established by the US National Academy of Sciences, whose aim was to examine the state of progress in computational linguistics in general and machine translation in particular. The committee’s report issued in 1966 was very sceptical of the research progress in MT, concluding that there was “no immediate or predictable prospect of useful machine translation” (p.32). It emphasized the need for basic investigations in computational linguistics instead. Consequently, there was a drastically cut in funding for machine translation in the US, as well as a remarkable decrease of interest in this research topic.

ALPAC report. PDF source: https://www.mt-archive.net/50/ALPAC-1966.pdf

ALPAC report concluding that there was “no immediate or predictable prospect of useful machine translation” (p.32). Source of PDF: https://www.mt-archive.net/50/ALPAC-1966.pdf
Stagnation of MT research in China (1966-1975)
Between 1966 and 1975, there was a stagnation in MT research in China as well, “not because of a shortage of funding” {Qian, 2023 #5727, p.306}, but partly due to the political and social upheaval in the Cultural Revolution and partly because of “the development of automatic translation outside of China” {Chan, 2004 #1881, p.305}.
From a technical perspective, this stagnation was also the result of “insufficiency in linguistic studies, inadequacy of the computers available for MT systems, and the barrier of Chinese ideograms” {Dong, 1988 #5726, p.86}. While the first two reasons were common to most MT research worldwide at the time, the third (i.e., the processing of Chinese ideograms) was unique to the Chinese language and was a bottleneck for MT even when computer applications became more popular in China. There was no satisfactory solution until the early 1980s.
References
Qian, Duoxiu. (2023). Translation technology in China. In S.-w. Chan (Ed.), Routledge Encyclopedia of Translation Technology (2nd Edition) (pp. 305-315). London and New York: Routledge.
Chan, Sin-wai. (2004). A dictionary of translation technology. Hong Kong: Chinese University Press.
Dong, Zhendong. (1988). MT research in China. In D. Maxwell, K. Schubert, & T. Witkam (Eds.), New Directions in Machine Translation (pp. 85-91). Dordrecht-Holland: Foris Publications.
MT at the ISTIC in China (1975)
In 1975, a machine translation group was jointly set up at the Institute of Scientific and Technical Information of China (中國科學技術情報研究所) by members of three institutions, namely, the Institute of Linguistics, the Institute of Computing Technology, and the Institute of Scientific and Technical Information. Their first project was an MT system that translated 5,000 titles from metallurgical literature.

Logo of the institute. Source: https://www.istic.ac.cn/html/1/529/558/index.html
The institute was established in 1956 as 中國科學院情報研究所. Its Chinese name was changed in 1958 to 中國科學技術情報研究所, then to 中國科學技術信息研究所 in 1992.

Source: Wikipedia https://zh.wikipedia.org/zh-cn/%E4%B8%AD%E5%9B%BD%E7%A7%91%E5%AD%A6%E6%8A%80%E6%9C%AF%E4%BF%A1%E6%81%AF%E7%A0%94%E7%A9%B6%E6%89%80#/media/File:Institute_of_Scientific_and_Technical_Information_of_China_(20231116103703).jpg

Source: https://www.istic.ac.cn/html/1/529/558/577/index.html

Source: https://baike.baidu.com/pic/%E4%B8%AD%E5%9B%BD%E7%A4%BE%E4%BC%9A%E7%A7%91%E5%AD%A6%E9%99%A2%E8%AF%AD%E8%A8%80%E7%A0%94%E7%A9%B6%E6%89%80/4261039/1/63d9f2d3572c11df0ebffc98682762d0f703c21b?fromModule=lemma_top-image&ct=single#aid=1&pic=63d9f2d3572c11df0ebffc98682762d0f703c21b

Source: http://ling.cass.cn/

source: http://english.ict.cas.cn/about/brief/

Source: http://www.ict.cas.cn/

Source: Wikipedia. https://zh.wikipedia.org/zh-tw/%E4%B8%AD%E5%9B%BD%E7%A7%91%E5%AD%A6%E9%99%A2%E8%AE%A1%E7%AE%97%E6%8A%80%E6%9C%AF%E7%A0%94%E7%A9%B6%E6%89%80#/media/File:Institute_of_Computing_Technology,_Chinese_Academy_of_Sciences_(20221018161524).jpg
ICT in China (1978)
In April 1978, researchers at the Institute of Computing Technology tested a general algorithm for translating English, German, and French titles into Chinese.
In May of the same year, satisfactory results were obtained from a test of English-to-Chinese translation of titles, via an 111-computer (64kw) and a sample of 20 English titles, at the Institute of Computing Technology. At that time, there was still no available Chinese character output device, so the output was given in Pinyin.
Other MT research centres in China (1978-1979)
In the second half of 1978, a few other centres for the research into MT were established in China, in addition to the MT group at the ISTIC. This included: the Machine Translation Section at the Institute of Linguistics, the English-Chinese Machine Translation Centre at Heilongjiang University, and the Russian-Chinese Machine Translation Centre at Harbin Polytechnic University {now known as Harbin Institute of Technology, see, e.g., \Peterson, 2001 #5731, pp.9-10}.
In 1979, research on MT in these centres in China became more active, and four algorithms were created. One of them was created by the joint group at the Institute of Linguistics, one by the Institute of Computation, one by the joint group at the Institute of Scientific and Technical Information, and one by the MT group of Heilongjiang University. {Chan, 2004 #1881, p.313}.

Heilongjiang University 黑龍江大學. Source: Wikipedia. https://en.wikipedia.org/wiki/Heilongjiang_University#/media/File:Heilongjiang_University.jpg

Source: Wikipedia. https://en.wikipedia.org/wiki/Heilongjiang_University#/media/File:Heilongjiang_University_logo.png

Harbin Polytechnical University (now known as Harbin Institute of Technology) 哈爾濱工業大學. Source: https://en.wikipedia.org/wiki/Harbin_Institute_of_Technology#/media/File:Harbin_Institute_of_Technology_(crest).gif

Source: https://en.wikipedia.org/wiki/Harbin_Institute_of_Technology#/media/File:Harbin_Institute_of_Technology_-_Main_Bldg.jpg
References
Peterson, Glen, & Ruth Hayhoe. (2001). Introduction. In G. Peterson, R. Hayhoe, & Y. Lu (Eds.), Education, Culture, and Identity in Twentieth-Century China (pp. 1-21). Hong Kong: Hong Kong University Press.
Chan, Sin-wai. (2004). A dictionary of translation technology. Hong Kong: Chinese University Press.
European project and Eurotra (1978)
In February 1978, the Commission of the European Community (CEC) decided to launch a research project on MT in Europe, and experts from universities were invited to participate in the design of the system. A multilingual MT system called Eurotra was invented by 1982.
Details of Eurotra are described in three edited volumes published by the Office for Official Publications of the Commission of the European Community, respectively entitled The Eurotra Linguistic Specifications (Vol. 1), The Eurotra Formal Specifications (Vol. 2), and Preference in Eurotra (Vol. 3). These were part of the book series Studies in Machine Translation and Natural Language Processing, which also includes some other books on different topics that are related to this area.

Flag of the European Community. Source: Wikipedia. https://en.wikipedia.org/wiki/European_Economic_Community#/media/File:Flag_of_Europe.svg
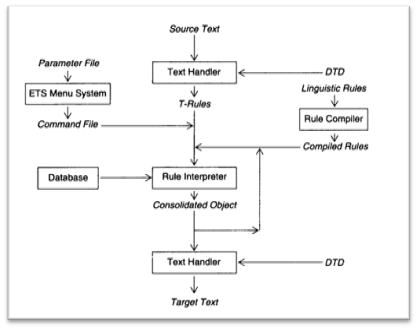
A diagram showing the data flow through the Eurotra framework. Here, programs are in boxes and files are in italics. From {Cencioni, 1991 #5736, p.130}
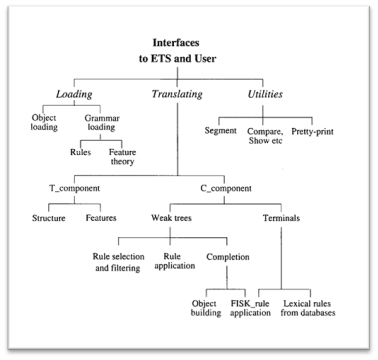
Diagram showing how the engine is split into modules. From {Cencioni, 1991 #5736, p.123}
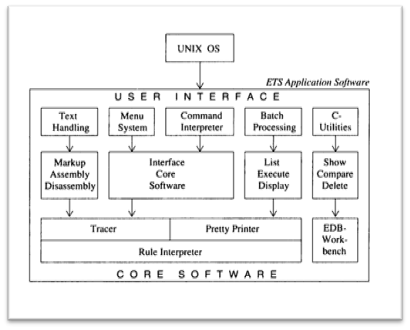
Major components of a prototype software (called ETS) in the Eurotra-framework. Diagram from {Cencioni, 1991 #5736, p.118}



The first three volumes of Studies in Machine Translation and Natural Language Processing. PDF documents are available here: https://op.europa.eu/en/related-publications?p_p_id=eu_europa_publications_portlet_search_executor_SearchExecutorPortlet_INSTANCE_AOrXQXg7DLjE&p_p_lifecycle=1&p_p_state=normal&_publicationDetails_PublicationDetailsPortlet_cellarId=24f88f17-0ede-4da8-b6a5-9556ae196433&_publicationDetails_PublicationDetailsPortlet_language=en&domain=EUPub&domain=EULex&domain=EUWebPage&domain=EUSummariesOfLegislation&facet.issn=1017-6568&p_p_parallel=0
References
Cencioni, Roberto. (1991). The Eurotra Software Environment - A Braod Overview. In C. Copeland, J. Durand, S. Krauwer, & B. Maegaard (Eds.), The Eurotra Formal Specifications (Vol. 2, pp. 113-133). Luxembourg: Office for Official Publications of the European Communities.
First national conference on MT in China (1980)
In 1980, the first national conference on MT in China was held in Beijing. The organizer of this conference was China Society for Scientific and Technical Information and there were 34 papers presented.
CIPS (1981, 1983)
In 1981, the Chinese Information Processing Society of China (CIPS) was established to promote the study of areas related to the processing of information in Chinese, such as machine translation, artificial intelligence, etc. The official academic journal of the society is Journal of Chinese Information Processing 《中文信息學報》.

Official logo of the society. Screenshot from https://www.cipsc.org.cn/index.aspx
The Chinese Information Processing Society of China set up the Special Committee on Natural Language Processing (中文信息研究會自然語言處理專業委員會) in Wuhan in 1983, and the Committee subsequently held an international conference on Chinese information processing in Beijing in the same year. Some of the Chinese scholars working on machine translation shared their research at the conference.
Computer Processing of Oriental Languages (1983)
In summer 1983, Computer Processing of Oriental Languages was founded in Singapore, covering all aspects of the computer processing of oriental languages.
ArchTran (1985)
In May 1985, The ArchTran machine translation system, which was among the first commercialized English-to-Chinese systems in the world {Chen, 1991 #5747}, started to be developed as a joint effort between National Tsing Hua University and Behavior Tech Computer Corporation (BTC). A prototype of the system was released in 1989 (ibid).
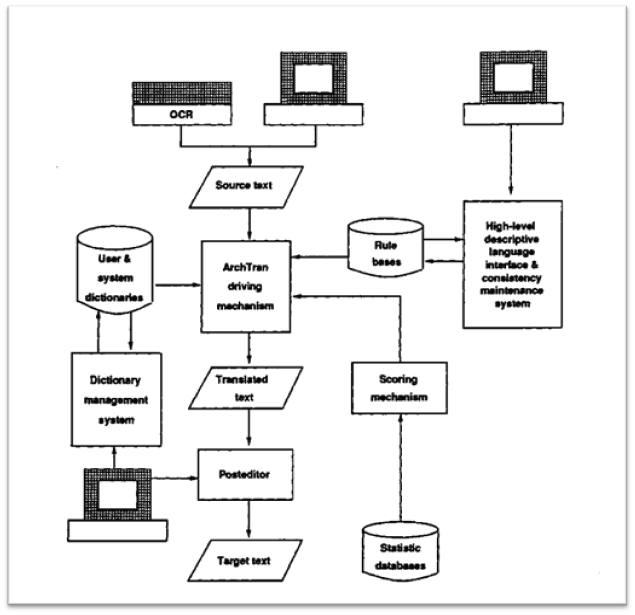
Archtran translation environment. Figure from (Chen 1991)
References
Chen, Shu-Chuan, Jing-Shin Chang, Jong-Nae Wang, & Keh-Yih Su. (1991). ArchTran: A corpus-based statistics-oriented English-Chinese machine translation system. Paper presented at the MT Summit III, Washington, DC, USA.
Journal of Chinese Information Processing (1986)
In 1986, the first issue of the Journal of Chinese Information Processing was published by Chinese Information Processing Society and the Institute of Software, Chinese Academy of Sciences. Since then, the journal has become “one of the leading journals in the field of computer science, artificial intelligence, and machine translation” {Chan, 2004 #1881, p.322}.

Picture source: http://jcip.cipsc.org.cn/CN/archive_by_covers
References
Chan, Sin-wai. (2004). A dictionary of translation technology. Hong Kong: Chinese University Press.
KY1 (1987)
In 1987, a translation software named Ke Yi Yi Hao 科譯一號 (KY1) was produced by Dong Zhendong 董振東 and Zhang Deling 張德玲 of the Research Institute of the Academy of Military Science 軍事科學院研究所. This was a milestone in the development of translation technology in China. It “won the second prize of the National Scientific and Technical Progress Award and was later further refined into TranStar, the first commercialized machine translation system in China” {Qian, 2023 #5727, p.306}.
References
Qian, Duoxiu. (2023). Translation technology in China. In S.-w. Chan (Ed.), Routledge Encyclopedia of Translation Technology (2nd Edition) (pp. 305-315). London and New York: Routledge.
TranStar, Kingsoft, and BehaviorTran (1988)
In 1988, the TranStar English-Chinese Machine Translation System was put into market as the first machine translation product in China. The system was developed by China National Computer Software and Technology Service Corporation. Since then, more than ten MT products became available in the market {Fu, 1999 #5729, p.86}.
In the same year, the Kingsoft Company 金山公司 was founded as a translation software company.
Also in 1988, an English-Chinese machine translation system named BehaviorTran was launched in Taiwan. The system was designed mainly by Su Keh-Yih and Chang Jing-Shin.
References
Fu, Aiping. (1999). The research and development of machine translation in China. Paper presented at the MT Summit VII, Singapore.
IBM and statistical MT (1988)
In the US, the Thomas J. Watson Research Center at IBM “revived statistical MT methods that equated parallel texts, then calculated the probabilities that words in one version would correspond to words in another” {Chan, 2004 #1881, p.327}.
References
Chan, Sin-wai. (2004). A dictionary of translation technology. Hong Kong: Chinese University Press.
DARPA (1990)
In 1990, the Defense Advanced Research Projects Agency (DARPA) launched the Spoken Language Systems programme and began developing voice-activated human-machine interaction tools.

Picture from: https://upload.wikimedia.org/wikipedia/commons/thumb/c/ce/DARPA_Logo_2010.png/220px-DARPA_Logo_2010.png
EAMT (1991)
In 1991, the European Association for Machine Translation (EAMT) was established as a non-profit organization serving the growing community of users, developers, and researchers in machine translation and various tools that aid human translation. The EAMT is registered in Switzerland and is one of three regional associations of the International Association for Machine Translation (IAMT). Its sister organizations are the Association for Machine Translation in the Americas (AMTA) and the Asia-Pacific Association for Machine Translation (AAMT).
The EAMT publishes a newsletter named MT News International, and regularly organizes various workshops and conferences including the MT Summit.

Logo of the EAMT. Picture from https://eamt.org/

Screenshot of the first page of the proceedings of EAMT annual conference 2023, held in Finland. PDF available at https://events.tuni.fi/uploads/2023/06/11678752-proceedings-eamt2023.pdf
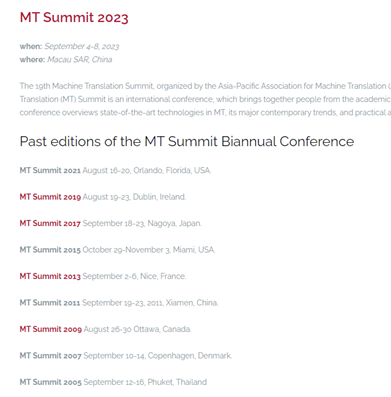
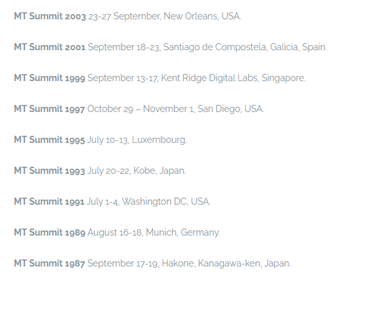
Dates and locations of the MT Summit Biannual Conference. From https://eamt.org/mt-summit-biannual-conference/
IMT/EC-863 (1995)
In 1995, the IMT/EC-863 English-Chinese Machine Translation System, which was developed by the Institute of Computing Technology of Chinese Academy of Sciences, received the first prize of the National Scientific and Technical Progress Award.
Machine Translation Review (1995)
In 1995, the periodical of the Natural Language Specialist Group of the British Computer Society, Machine Translation Review, published its first issue. It incorporates articles, book reviews, advertisements, and all items of information relating to the processing and translation of natural language, and appears twice a year.


Screenshot of the first issue of Machine Translation Review. PDF available at https://mt-archive.net/90/MTR-1.pdf
SUSY (1995)
Since 1995, the SUSY system (Saarbrücker Übersetzungssystem / The Saarbrucken Machine Translation System) in Germany has been used online for German-to-English and Russian-to-German machine translation. This project was developed between 1972 and 1986, while the system was put to use between 1981 and 1990. Saarbrucken is the largest and the most established machine translation group in Germany {Chan, 2004 #1881, p.333-334}.
Outline of the overall system design of SUSY. Source: {Freigang, 1986 #5756, p.86}
References
Chan, Sin-wai. (2004). A dictionary of translation technology. Hong Kong: Chinese University Press.
Freigang, Karl-Heinz. (1986). Research on machine translation at the University of Saarbrücken. Paper presented at the Translating and the Computer 8: A profession on the move, London, UK. Aslib. https://aclanthology.org/1986.tc-1.12.pdf
Dong Fang Kuai Che (1997)
A machine translation software named Dong Fang Kuai Che (東方快車) was developed and commercially available in China. This software became very popular among Chinese users at that time. Main versions of the software include Dong Fang Kuai Che 98, 2000, 3000, 2003, etc. The software includes various tools, e.g., a full-text translation tool called Dong Fang Kuai Wen (東方快文), a dictionary tool named Dong Fang Kuai Dian (東方快典), a software localization tool Yong Jiu Han Hua (永久漢化), a webpage translation tool for Internet Explorer named Dong Fang Wang Yi (東方網譯), etc.
Picture from https://www.sohu.com/a/308805820_100287953#google_vignette
TransBridge (1997)
In Taiwan, a company named TransBridge was founded in 1997, whose main product was “TransBridge Instant English to Chinese Translator” (Yi Qiao Quan Gong Neng Ji Shi Fan Yi Xi Tong).

Pictured cropped from https://www.ruten.com.tw/item/show?22248786355068
SDL WebFlow (1999, UK)
SDL WebFlow was released by SDL, which could translate a website into various target languages within seconds. SDL WebFlow is a suite of products and services, solving issues related to managing multiple international websites. It delivers a “One-Stop-Solution” to the issues of managing multiple international websites.
BULTRA (2000, Bulgaria)
The first English-Bulgarian MT tool, BULTRA, was finalized by Pro Langs in Bulgaria.
Computer-aided translation
Déjà Vu (1993)
In 1993, the first version of Déjà Vu was developed by Atril. This is a customizable CAT system where translation memory is integrated with example-based MT. This version used the Microsoft Word interface, and in 1996, the software was given its own program interface instead.
MultiTrans (1993)
In 1993, a user-friendly CAT system called MultiTrans was produced by MultiCorpora. Previously translated files can be indexed, resulting in a bilingual corpus in which the user can search for words, expressions, and sentences.
TERMIUM (1976)
In 1976, the Secretary of State of Canada officially acquired a terminology database called BTUM (Banque de Terminologie de l’Université de Montréal), and renamed it TERMIUM (TERMInologie Université de Montréal). This is an electronic terminology and linguistic data bank of the government of Canada, operated and maintained by the Translation Bureau in Canada.
It is now one of the largest terminology and linguistic data banks in the world, allowing access to millions of terms in English, French, Spanish, and Portuguese. Users can find terms, abbreviations, definitions, and usage examples in a wide range of specialized fields. This is useful for understanding an acronym, checking an official title, finding an equivalent in another language, etc.
Screenshot of the official webpage. Link: https://www.btb.termiumplus.gc.ca/tpv2alpha/alpha-eng.html?lang=eng
The Localisation Research Centre (1995)
In 1995, the Localisation Research Centre was established as the Localisation Resources Centre at University College Dublin (UCD), Ireland. It later moved to the University of Limerick (UL) and re-constituted as the Localisation Research Centre. This is a centre for research, education, and outreach activities in the areas of localization, internationalization, and translation technology in the Department of Computer Science and Information Systems at the University of Limerick, Ireland.
From July to December 1996, the Centre published a quarterly newsletter named Software Localisation, and from March 1997 to March 2002 the publication was renamed as Localisation Ireland. Since June 2002 it has gradually become totally research-driven and was named Localisation Focus – the International Journal of Localisation. The journal was peer-reviewed, focused exclusively on localization and the localization industry, and published on an annual basis.

University of Limerick. Picture source: https://www.limerickleader.ie/news/home/1460150/breaking-university-of-limerick-chancellor-calls-special-meeting-of-all-students-and-staff.html

Cover page of the journal (Vol. 14, Issue 2). PDF available at: https://www.localisation.ie/wp-content/uploads/2022/02/Vol-14-Issue-2-hq.pdf
Translational English Corpus (1995)
As proposed by Mona Baker, the Centre for Translation and Intercultural Studies, University of Manchester Institute of Science and Technology (UMIST) set up the Translational English Corpus (TEC), which was funded by the British Academy. This is a collection of digital text which was translated into English from other languages, in the categories of biography, fiction, newspapers, and inflight magazines.
Yiba CAT system (1997)
A computer-aided translation system named Yiba was developed by Beijing YaxinCheng Software Technology Co. Ltd.
Yaxin CAT (1999)
In 1999, the Shida CAT Research Centre (實達CAT研究中心) was set up by Beijing YaxinCheng Software Technology Co. Ltd., and the company developed YaxinCAT 2.5 Bidirectional Version which was at the time one of the most famous CAT products in China. This was acquired by SJTU Sunway Software Industry Ltd. In August, Yaxin CAT v1.0 was released.
Yaxin CAT is China’s first all-in-one computer-aided translation system, integrating translation memory, human-machine interaction, and analysis (Qian 2023). Today, Yaxin CAT 4.0 is commercially available as a popular tool among Chinese CAT users (ibid). The release of this software “signified, in a small way, that the development of computer-aided systems was no longer a European monopoly” (Chan 2023, p.10).
Picture: https://m.91zhuti.com/sf/36713.html
References
Qian, Duoxiu. (2023). Translation technology in China. In S.-w. Chan (Ed.), Routledge Encyclopedia of Translation Technology (2nd Edition) (pp. 305-315). London and New York: Routledge.
Chan, Sin-wai. (2023). The Development of Translation Technology. In S.-w. Chan (Ed.), The Routledge Encyclopedia of Translation Technology (pp. 3-41). London and New York: Routledge.
Wordfast Plus Tools (1999)
In France, the first version of the Wordfast Plus Tools suit was developed, which could be freely downloaded before 2002 upon registration.
Picture source: https://www.wordfast.net/wiki/Auto-Suggest_in_Wordfast_Pro
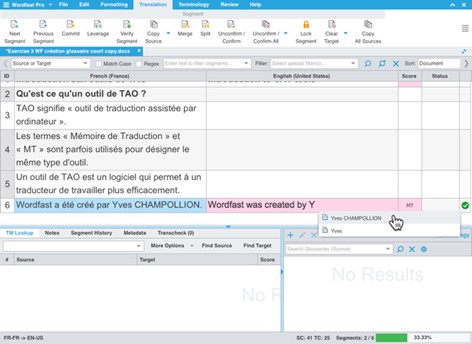
SDL Workbench (1999)
In the UK, SDL International announced SDL Workbench which was packaged with SDLX, a translation database tool. It could automatically provide the user with possible translations and terminology from the user’s database within a Microsoft Word environment. The tool was compatible with a variety of file formats, e.g., Trados and pre-translated RTF files.
Picture from http://www.globalsight.com/wiki/index.php/Translating_with_Trados_Workbench
OmegaT (2000)
In Germany, a free translation memory tool called OmegaT was released as a free, open-source software. It was written in Java and compatible with various operating systems.
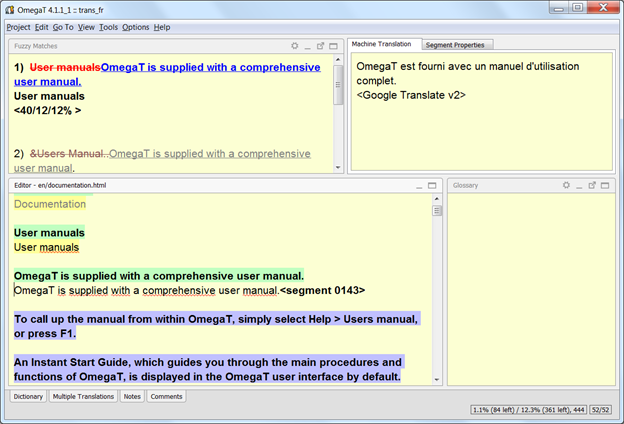
OmegaT 1.1.1. Picture from https://omegat.org/
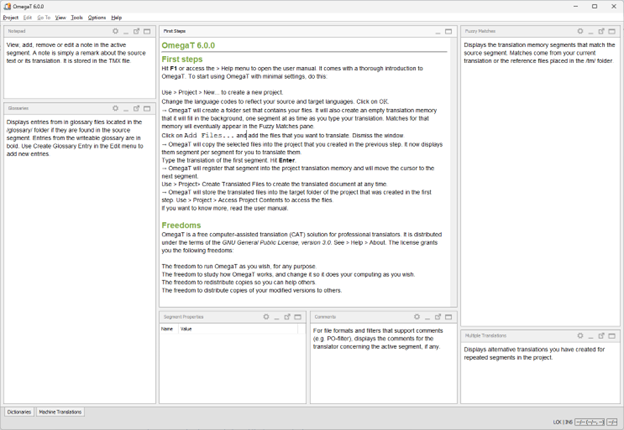
Screenshot of OmegaT 6.0.0
Huajian IAT (2002)
Huajian IAT, a computer-aided system, was released in China in 2002.
MemoQ (2005)
In Hungary, Kilgray Translation Technologies released the first version of MemoQ, an integrated translation management system. Their products included MemoQ, MemoQ server, QTerm, and TM Repository.
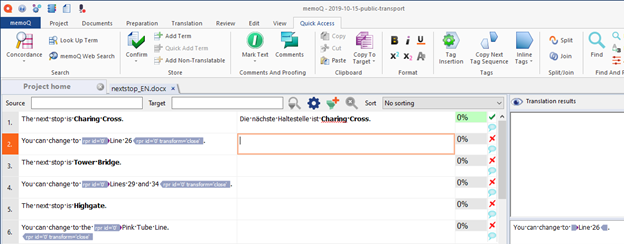
Picture from https://helpcenter.memoq.com/hc/en-us/articles/6015085799697-4-First-Translation-Typing-the-translations
Systran Professional Premium 5.0 (2004)
In the US, Systran Professional Premium 5.0 was released by Systran in 2004, containing such tools as integrated translation memory with TMX support, a translator’s workbench for post-editing, and quality analysis.
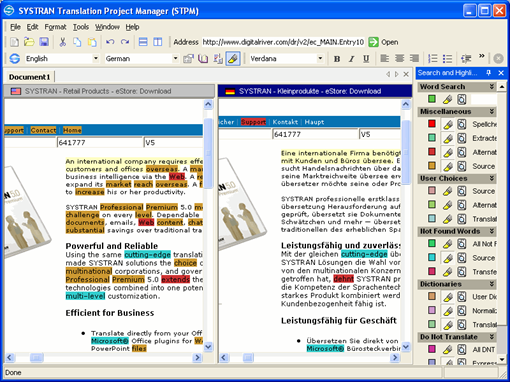
Picture from https://www.softreviews.org/Localize2/Systran/Systran5.html
Anymem (2008)
In Ukraine, Advanced International Translations (AIT) produced a user-friendly translation memory software called Anymem in 2008.
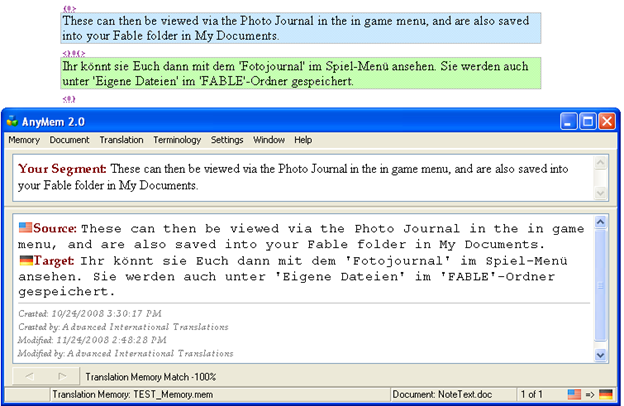
General view of the software. Picture from: https://www.anymem.com/images/stories/anymem/screenshots/translation_memory_operation.png
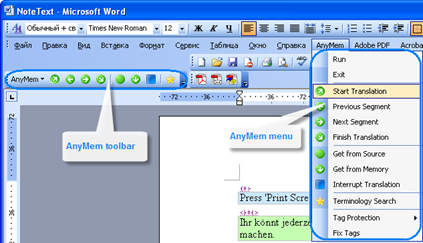
Built-in AnyMem menu in MS Word. Picture from https://www.anymem.com/images/stories/anymem/screenshots/builtin_word.png
Swordfish & Stingray (2008)
In Uruguay, a cross-platform computer-aided translation tool based on the XLIFF 1.2 open standard, which was named Swordfish, was launched by Maxprograms. The source code of Swordfish is open and available under the Eclipse Public License v1.0 at https://github.com/rmraya/Swordfish.
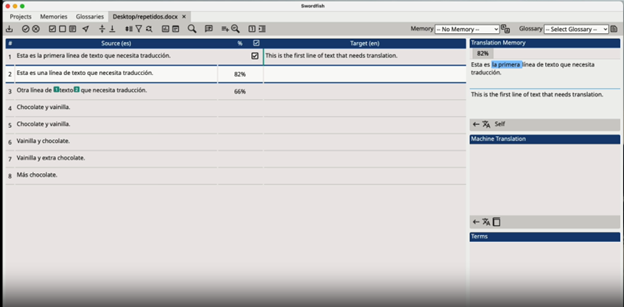
Screenshot from https://www.maxprograms.com/products/swordfish.html
In the same year, the company released Stingray, a cross-platform document aligner. The translation memories generated by Stingray could be used in most modern computer-aided translation systems. Same as Swordfish, the source code of this tool is open and available under the Eclipse Public License v1.0 (at https://github.com/rmraya/Stingray).
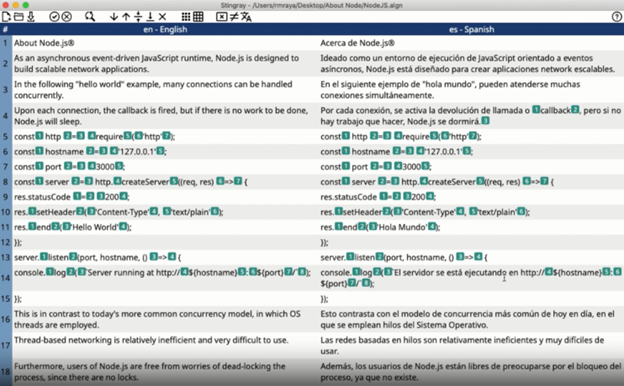
Screenshot from https://maxprograms.com/products/stingray.html
Alchemy (2008)
In Ireland, Alchemy PUBLISHER 2.0 was released by Alchemy Software Development. The software combined visual localization technology with translation memory for documentation.
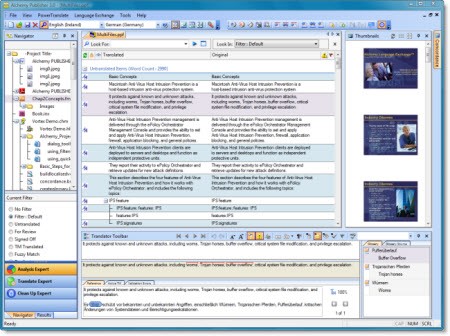
https://www.alchemysoftware.com/products/alchemy_publisher.html#
Autshumato Integrated Translation Environment (2009)
In South Africa, The Centre for Text Technology (CTexT) at the Potchefstroom Campus of the North-West University and University of Pretoria released Autshumato Integrated Translation Environment (ITE) version 1.0. The project was funded by the Department of Arts and Culture of the Republic of South Africa.
Autshumato Integrated Translation Environment is a free computer-aided translation system that provides a single translation environment containing translation memory, machine translation, and a glossary to facilitate the translation process. It is a derived work of the OmegaT CAT tool, customized for the South-African environment.
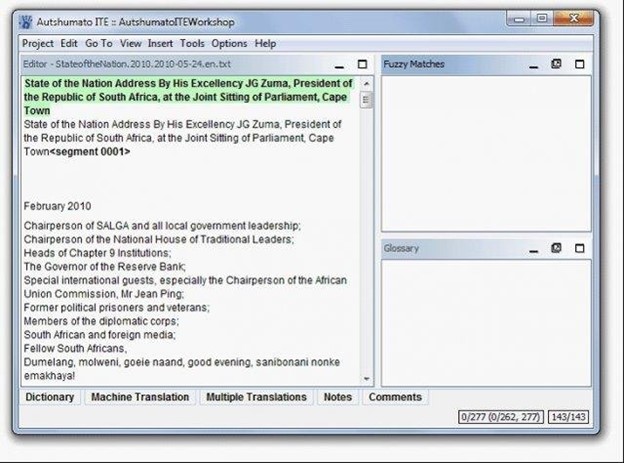
Picture from https://sourceforge.net/projects/autshumatoite/
Wordfast Translation Studio (2009)
In 2009, Wordfast Translation Studio was released as a bundled product with Wordfast Classic and Wordfast Pro. It was claimed as the second most widely used translation memory tool.
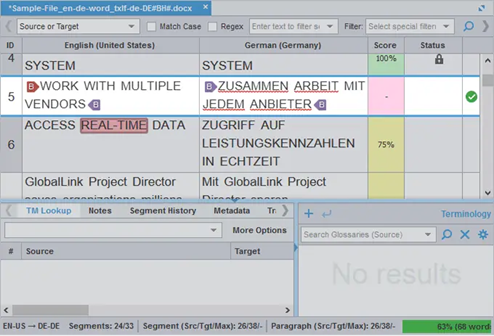
Picture from https://www.bureauworks.com/blog/the-top-5-cat-tools-for-translation-professionals
Trados (2009)
In the UK, SDL launched SDL Trados Studio 2009, which included a few tools that were already popular at the time, e.g., SDL MultiTerm, SDL Passolo Essential, SDL Trados WinAlign, and SDL Trados 2007 Suite. There were also new features such as Context Match, AutoSuggest, and QuickPlace.
In the same year, the enterprise platform SDL TM Server 2009 was released as a new solution to centralise, share, and control translation memories.
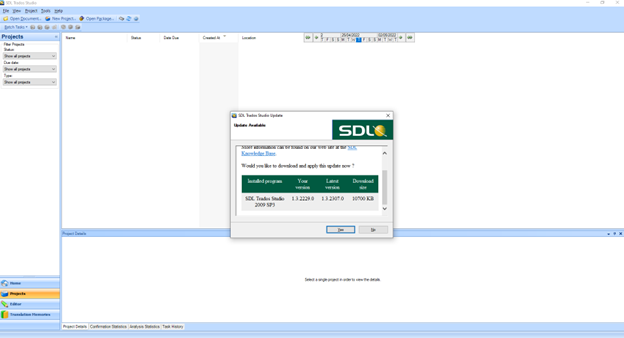
Picture from https://community.rws.com/product-groups/trados-portfolio/trados-studio/f/studio/41406/trados-studio-2009
Snowman CAT (2009)
In China, Foshan Snowman Computer Co. Ltd. released Snowman version 1.0. This is important because, as Chan {, 2023 #5702} describes,
(1) Snowman was new; (2) the green trial version of Snowman could be downloaded free of charge; (3) Snowman was easy to use, as its interface was user friendly and the system was easy to operate; and (4) Snowman had the language pair of Chinese and English that caters to the huge domestic market as well as the market abroad. (p.17)
Picture source: http://www.gcys.cn/shipin_old.html
(“客户端教学视频 – 02 WORD文档的翻译”)
References
Chan, Sin-wai. (2023). The Development of Translation Technology. In S.-w. Chan (Ed.), The Routledge Encyclopedia of Translation Technology (pp. 3-41). London and New York: Routledge.
XTM (2010)
In September 2010, XTM International released XTM Cloud, a totally online software-as-a-service (SaaS) computer-aided translation tool set
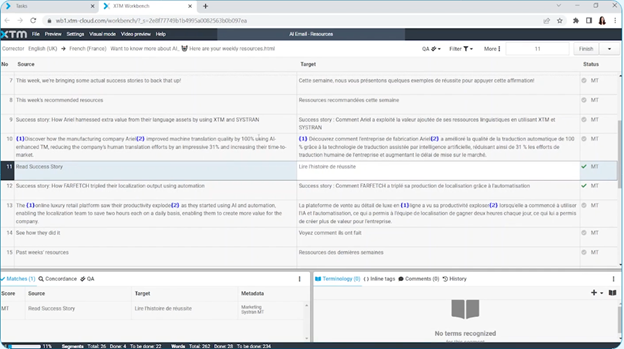
Screenshot from video at https://xtm.cloud/xtm-cloud/
DGT-TM (2011)
In 2011, the Directorate-General for Translation (DGT) of the European Commission (EC), together with the EC’s Joint Research Centre, updated their translation memory database (DGT-TM) which was created in 2007. At the time, the database contained sentences and their manually produced translations in 22 languages and 231 language pairs, comprising treaties, regulations, and directives. This update in 2011 contained documents published between 2004 and 2010, and the database became two times larger than the original release in 2007. Since then, the DGT-TM was updated and released on a yearly basis.
As of 2024, the DGT-TM contains a total of 180 million translation unites (see https://jeodpp.jrc.ec.europa.eu/ftp/jrc-opendata/DGT-TM/Resources/DGT-TM-2024/DGT-TM_Statistics.pdf
Transn, Snowman, and Transmate (2012)
In China, Transn Information Technology Co., Ltd. released TCAT 2.0 (傳神輔助翻譯系統) as a freeware. In the same year, Foshan Snowman Computer Co. Ltd. released the free version of Snowman Collaborative Translation Platform (雪人CAT協同翻譯平臺) which offers a server for a central translation memory and terbase.
Meanwhile, Chengdu Urelite Tech Co. Ltd. (成都優譯信息技術有限公司) released Transmate.
MemSource (2012)
In Czech Republic, MemSource Technologies released MemSource Editor as a free tool for translators which can work with MemSource Cloud and MemSource Server.
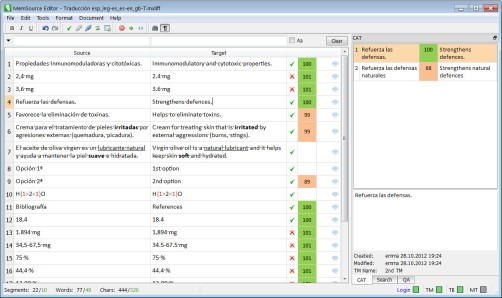
Picture from https://signsandsymptomsoftranslation.com/2012/11/09/memsource/
Teaching of translation technology
UMIST (1996, England)
In 1996, the Graduate School of the University of Manchester Institute of Science and Technology (UMIST) started offering their Master of Science programme in Machine Translation, aiming to equip students with an understanding of “how computational aids may be used to assist interlingual communication”.
Location of UMIST, Manchester, England.
LTI (1996, USA)
The Language Technologies Institute (LTI) at Carnegie Mellon University, which was initially established as the Center for Machine Translation in 1986, changed its name and began awarding degrees in 1996. It provides graduate education in all aspects of language technology. Today, the LTI offers five postgraduate degrees – the PhD in Language and Information Technology, the research-based Master of Language Technologies, and three professional master’s programmes.
Location of the LTI at Carnegie Mellon University, Pittsburgh, Pennsylvania, USA.
James Madison University (1999, USA)
A minor in translation was established at the James Madison University in Harrisonburg, Virginia, USA, with a focus on non-literary translation. The courses taught there also included Terminology, Computer Tools for Translators, Song Translation and Advertising Translation.
Location of the James Madison University, Harrisonburg, Virginia, USA.

Picture source: https://www.jmu.edu/_images/default/JMUopengraphimage.jpg
University of London (2001, England)
A one-year Master of Science programme in Scientific, Technical and Medical Translation was established at the Imperial College of Science, Technology and Medicine of the University of London. Areas taught in the programme included specialized translation, computer-assisted translation, and machine translation.

Picture source: https://www.imperial.ac.uk/visit/campuses/
The Chinese University of Hong Kong (2002, Hong Kong)
In September 2002, the Department of Translation at The Chinese University of Hong Kong started offering a Master of Arts programme in Computer-Aided Translation.

Picture source: https://wun.ac.uk/wun/members/view/cuhk/
TRIP, Binghamton University (2002, USA)
The Translation Research and Instruction Program (TRIP) was founded in 1971 at the State University of New York at Binghamton (also known as Binghamton University) to promote the study of translation. The doctoral degree offered by TRIP was the first PhD program in Translation Studies in the US. In 2002, TRIP organized a workshop on “Translation and Up-to-date Technologies” where hands-on skills of project management, terminology and graphics management, user interface project management, the use of computer-aided translation tools, and quality assessment procedures were introduced to the participants.

Picture source: https://www.collegetransitions.com/blog/how-to-get-into-binghmaton-university-acceptance-rate/
CRITT, Copenhagen Business School (2005, Denmark)
In June 2005, the Center for Research and Innovation in Translation and Translation Technology was established at Copenhagen Business School, where translation process and the technological innovations in the field of translation were studied. The research conducted there combined the human translation process research, computer modelling, machine translation, tree-bank annotation, and business application. The Center later moved to Kent State University in the USA.

Picture source: https://www.business-school.ed.ac.uk/about/news/institutional-visit-to-copenhagen-business-school-denmark
CRITT, Kent State University (2018, USA)
In 2018, the Center for Research and Innovation in Translation and Translation Technology (CRITT) moved to the Department of Modern and Classical Language Studies, Kent State University, Ohio, USA. Kent State University is the only institution in the US that offers degrees in translation at all three levels – the Bachelor of Science in Translation, the Master of Arts in Translation, and the PhD in Translation Studies. The study of translation is one of the major strengths of the department.
CRITT at Kent State University primarily aims to carry out research that builds up new knowledge of translation and communication processes and provide a basis for technological innovation in this field.
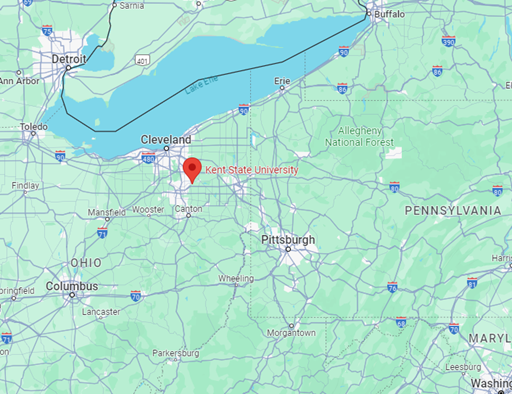
Location of Kent State University, Ohio, USA

Picture source: https://www.kent.edu/about
EMT (2009)
In 2009, the European Master’s in Translation (EMT) network published its framework for translator and translation competence. This framework was substantially redrafted in 2017, and has now “become one of the leading reference standards for translator training throughout the European Union and beyond, both in academia and industry” {EMT Network, 2022 #5766, p.2}.
In the training of translators at the Master’s level, “inclusion of substantial translation technology component is a requirement” {Chan, 2023 #5767, p.268}.
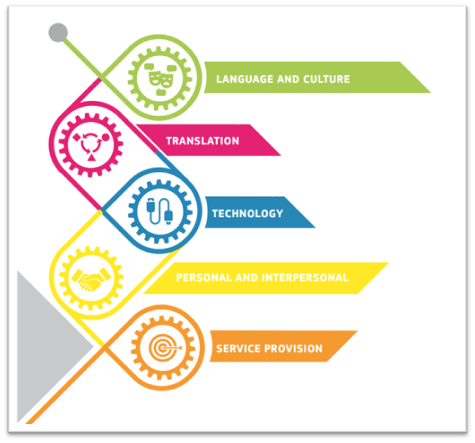
The five main areas of competence defined in the EMT framework. Picture from {EMT Network, 2022 #5766, p.4}
With respect to technology (ibid, p.9):

The EMT Network was established by the Directorate-General for Translation (DGT) at the European Commission.
Countries in the EMT Network. Picture cropped from https://paratraduccion.com/limiares/en/el-mtci-es-emt-master-europeo-en-traduccion/
References
EMT Network. (2022). European Master's Translation Competence Framework. European Commission. Retrieved from https://commission.europa.eu/document/download/b482a2c0-42df-4291-8bf8-923922ddc6e1_en?filename=emt_competence_fwk_2024_en.pdf
Chan, Venus, & Mark Shuttleworth. (2023). Teaching translation technology. In S.-w. Chan (Ed.), Routledge Encyclopedia of Translation Technology (2nd Edition) (pp. 259-279). London and New York: Routledge.
EM TTI
In addition, EU also hosts the European Master’s in Technology for Translation and Interpreting, which aims to train a new generation of professionals who leverage technological tools. It provides a high-quality academic programme aligned with Erasmus+ principles, delivered by a consortium of four universities (University of Wolverhampton, University of Malaga, New Bulgarian University, and Ghent University) known for their contributions to language and translation technology.

Picture from https://em-tti.eu/